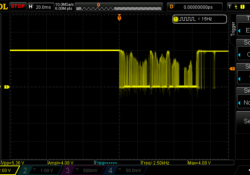
Initial release of mywayback
Mywayback is a complete rewrite of my previous timeback archival tool. It is now available on the github: https://github.com/jsyk/mywayback Main features: Python 3.x in Windows (with NTFS-only) and Linux. Requires the package sortedcontainers. Automatic deduplication of source files using SHA256… Continue Reading