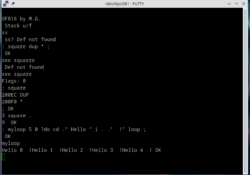
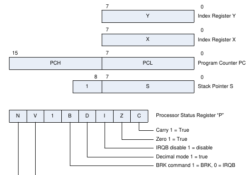
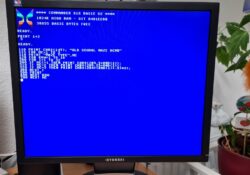
X65-SBC Video-Terminal for the Forth OF816 Interpreter
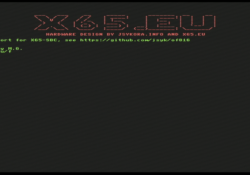
In the previous post I have mentioned that I am working on a port of the 32-bit Forth interpreter OF816 to my X65-SBC, an 8/16-bit retro computer that I am building. The software runs on the X65-SBC in the 65C816… Continue Reading